

들어가며
앞서서 모니터링과 관측가능성에 대해 정리했고, 이번 게시글에서는 OTel Demo를 통해 observability의 대표적인 도구인 Opentelemetry을 사용해서 어떻게 trace, metric, log 데이터를 수집하고 관리하는지에 대해 실습해 보겠습니다.
OpenTelemery
OpenTelemery란?
OpenTelemetry(OTel)는 애플리케이션과 인프라에서 관측가능성(Observability)을 구현하기 위한 오픈소스 프레임워크입니다. 즉, 메트릭(Metrics), 로그(Logs), 트레이스(Traces) 데이터를 수집하고 처리하여 내보낼 수 있도록 도와주는 도구입니다. 기존에는 관측가능성을 위한 다양한 도구들이 존재했지만, 각각의 솔루션이 독립적으로 작동하여 일관된 데이터 수집이 어려웠기에 OpenTelemetry는 이러한 문제를 해결하기 위해 CNCF(Cloud Native Computing Foundation)에서 개발한 프로젝트로, 다양한 백엔드(Prometheus, Jaeger, Zipkin 등)와 통합이 가능하도록 설계되었습니다.
Distributed Tracing
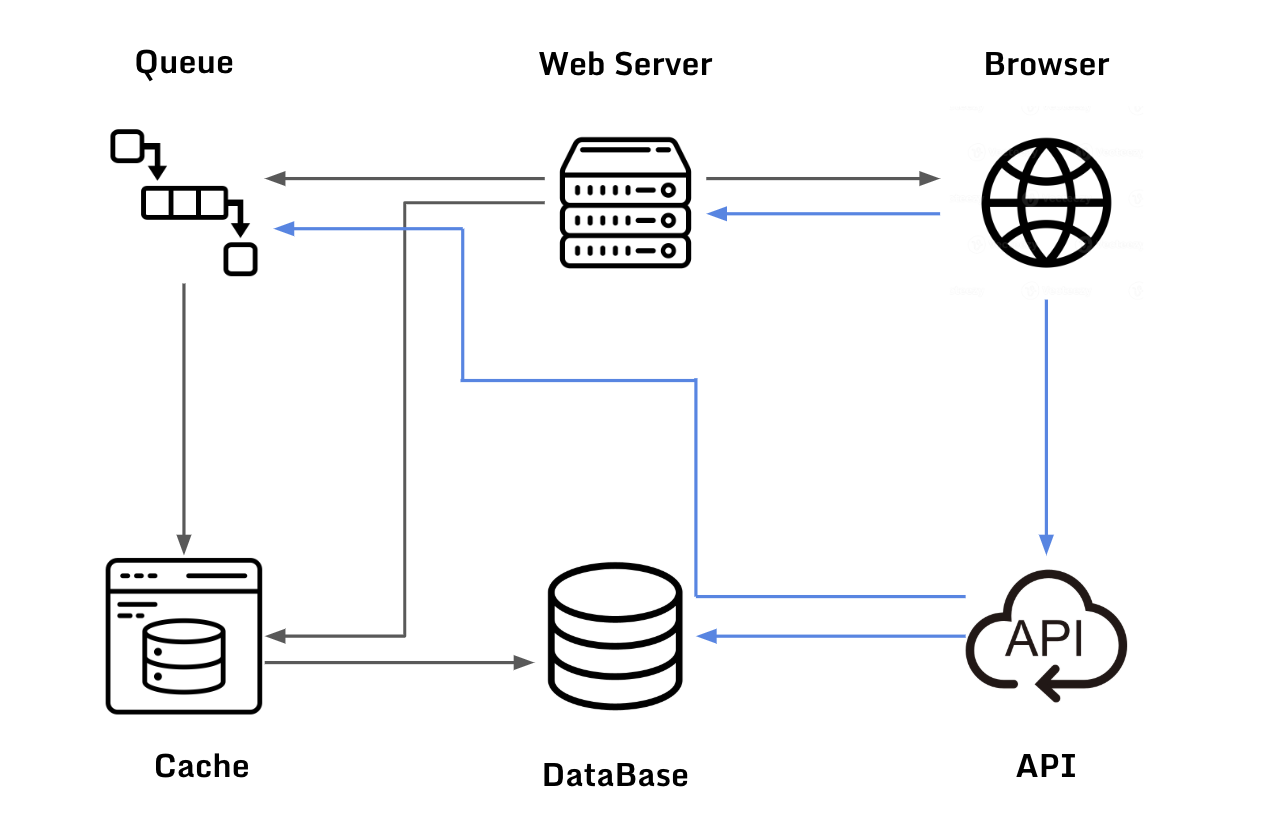
Distributed Tracing이란?
Otel을 실습하기 전에 분산 추적에 대해 알아보고 넘어가겠습니다.
Distributed Tracing(분산 추적)은 하나의 요청(Request)이 여러 마이크로서비스를 거치면서 어떻게 처리되는지 추적하는 기술입니다. 즉, 서비스 간 요청 흐름을 추적하고, 성능 문제나 병목 현상을 분석하는 데 사용되는 기술입니다.
모놀리식 시스템 vs 마이크로서비스
모놀리식 시스템에서는 요청이 단일 서버에서 처리되므로 디버깅이 비교적 쉬웠습니다. 하지만 MSA에서는 하나의 요청이 여러 개의 서비스를 거치면서 처리되기 때문에 어떤 서비스에서 어떤 문제가 발생했는지 추적하기 어렵습니다. 이때 Distributed Tracing을 통해 요청이 어떤 서비스들을 거쳐 갔는지 시각적으로 확인이 가능하여 각 서비스에서 걸린 시간(latency)을 분석하여 병목 현상의 원인을 찾을 수 있고, 특정 요청에서 발생 오류들을 추적하고 분석이 가능합니다.
핵심 개념
Trace
하나의 요청이 시스템을 거치는 전체 과정으로 예를 들어 사용자가 로그인 버튼을 눌렀을 때 요청이 API -> Auth Server -> DB -> 응답으로 돌아오는 흐름을 하나의 Trace라고 합니다.
Span
Trace를 구성하는 개별 작업 단위로서 하나의 요청(Trace) 안에서 특정 서비스나 작업이 수행된 시간을 나타냅니다. 이때 시작 및 종료 타임스팸프로 특징지어지고 추적 ID와 스팬 ID 쌍으로 고유하게 식별됩니다.
TraceID
요청을 추적하기 위해 모든 Span에 공통적으로 부여되는 ID dlqslek.
Parent - Child 관계
서비스 간 호출은 부모-자식(Parent-Child) 관계로 트레이싱됩니다.
Tracing 예시
사용자가 로그인을 했을 시에 발생한 Tracing을 예시로 한번 나타내보겠습니다.
트레이싱 구조
Trace ID: 12345 (사용자 로그인 요청)
├── Span 1: API Gateway (200ms)
│ ├── Span 2: Auth Service (150ms)
│ │ ├── Span 3: DB Query (50ms)
│ │ ├── Span 4: JWT Token 생성 (30ms)
│ ├── Span 5: 캐시 조회 (20ms)
1. 사용자가 로그인 요청 : client -> API Gateway
2. 로그인 시도 : API Gateway -> Auth Service
3. 사용자 정보 조회 : Auth Service -> DB
4. DB 응답 후 JWT Token 생성 : DB -> Auth Service
5. 사용자에게 응답 전달 : Auth Service -> API Gateway
이때, 만약 DB Query에서 응답 시간이 오래 걸리면 병목(Bottleneck)으로 판별할 수 있게 됩니다.
OpenTelemetry Demo를 활용한 실습
https://github.com/open-telemetry/opentelemetry-demo
GitHub - open-telemetry/opentelemetry-demo: This repository contains the OpenTelemetry Astronomy Shop, a microservice-based dist
This repository contains the OpenTelemetry Astronomy Shop, a microservice-based distributed system intended to illustrate the implementation of OpenTelemetry in a near real-world environment. - ope...
github.com
실습은 위 OpenTelemetry Demo를 이용하여 진행해 보겠습니다. 위 레포지토리는 OpenTelemetry를 실제와 유사한 환경에서 보여주기 위해 구현된 데모입니다.
실습 조건
- Kubernetes 1.24+
- 6 GB of free RAM for the application
- Helm 3.14+ (for Helm installation method only)
Otel Demo 설치
helm을 통한 설치(권장)
helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
helm install my-otel-demo open-telemetry/opentelemetry-demo

kubectl을 사용하여 설치
kubectl apply --namespace otel-demo -f https://raw.githubusercontent.com/open-telemetry/opentelemetry-demo/main/kubernetes/opentelemetry-demo.yaml
애플리케이션 접근을 위해 Port forward 설정
kubectl port-forward svc/frontend-proxy 8080:8080
데모 애플리케이션을 사용하려면 K8s cluster 외부에서도 서비스에 접근할 수 있도록 노출해야 합니다.
애플리케이션 접근
http://localhost:8080/
jaeger ui 접근
http://localhost:8080/jaeger/ui/
임의의 trace를 선택하면 서비스 간 호출 내역과 각 서비스에서 소요된 시간을 확인할 수 있습니다. 위처럼 시각화된 지표들을 통해 애플리케이션의 성능상 병목지점을 식별할 수 있습니다.
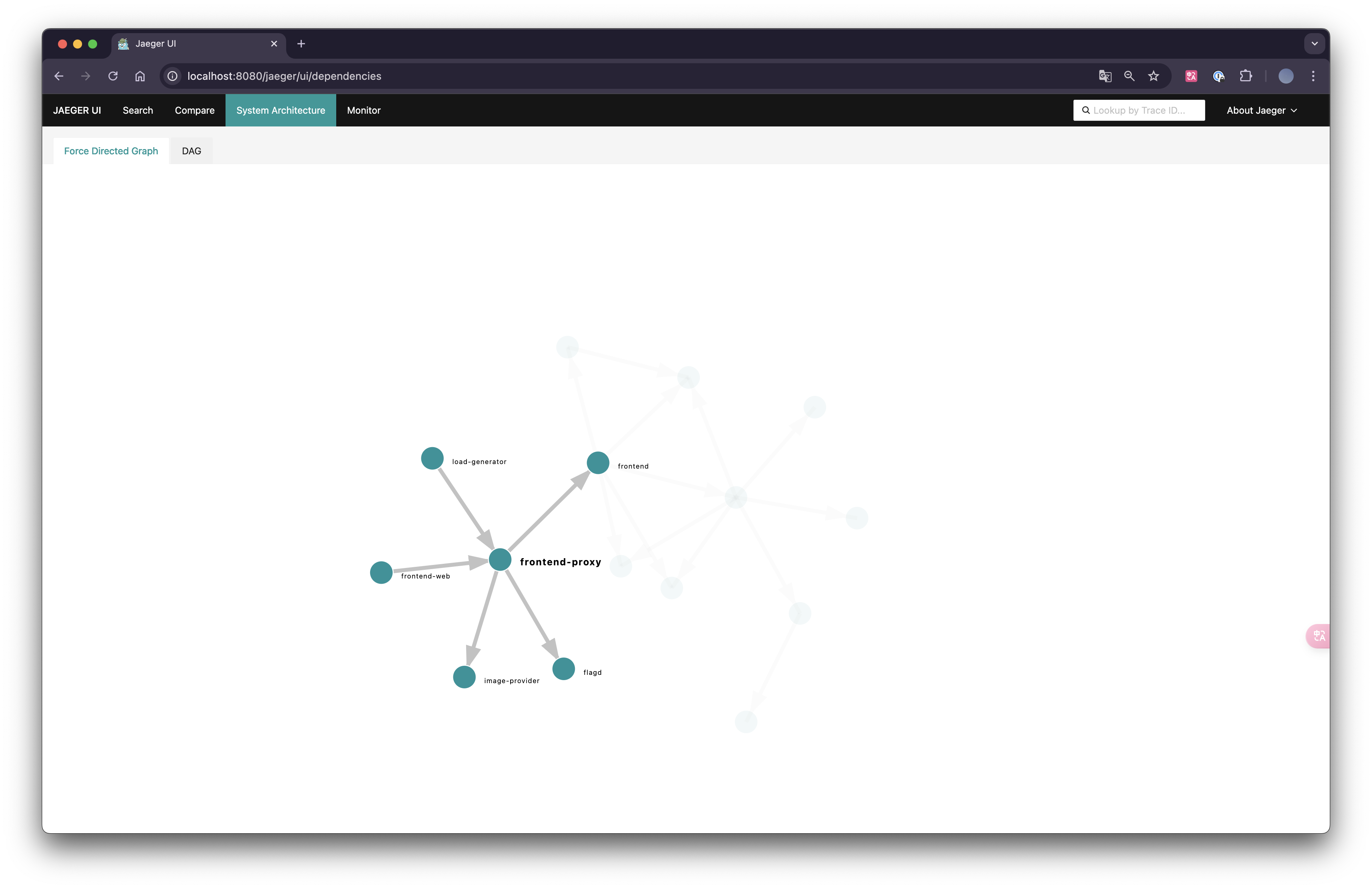


Jaeger에는 System Architecture라는 메뉴가 있는데, 이 메뉴를 통해 서비스 간의 상호작용을 그래프로 시각화할 수 있습니다. 특정 서비스를 클릭하면 해당 서비스와 연관된 모든 서비스가 보이며, 서비스 간의 의존성과 호출 관계를 쉽게 파악할 수 있습니다.
grafana 접근
http://localhost:8080/grafana

http://localhost:8080/grafana/dashboards
미리 설정된 dashboard를 통해 데이터 수집에 대해 시각화하여 볼 수 있습니다.

loadgen 접근
http://localhost:8080/loadgen/
load generator는 Locust를 사용하여 사용자 트래픽에 대해 부하테스트 환경을 구축할 수 있는 오픈소스 도구입니다.
prometheus 서비스(ClusterIP) 포트 포워딩 설정
kubectl --namespace default port-forward svc/prometheus 9090:9090 &
prometheus 접근
http://localhost:9090/
실습 시나리오 - 메모리 누수 진단
Metric과 Trace를 분석하여 메모리 누수의 원인을 파악하는 실습을 진행해 보겠습니다.
대시보드 확인
문제를 진단하는 첫 번째 단계는 문제가 있는지 확인하는 것이기 때문에 Grafana와 같은 도구에서 제공하는 메트릭 대시보드를 통해 확인합니다.

위의 주소로 접근하면 OTel Demo를 설치하였을 때 생성된 Dashboard들이 보이는데, 이때 OpenTelemetry Collector를 모니터링하는 대시보드와 각 서비스의 대기 시간과 요청 속도를 분석하기 위한 여러 쿼리 및 차트가 포함되어 있는 대시보드가 존재합니다.
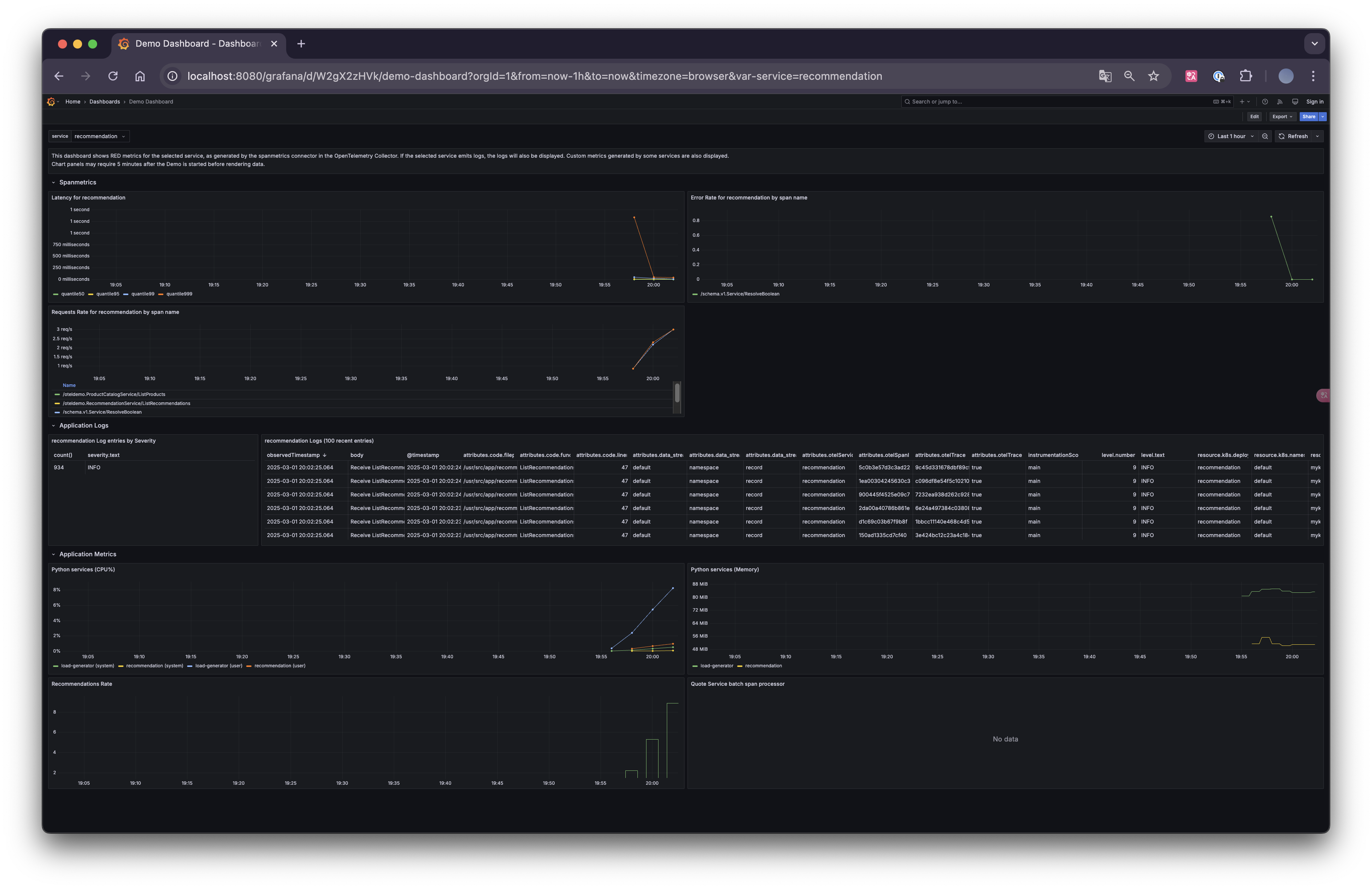
이 대시보드에는 여러 차트가 포함되어 있습니다. 이 중 Recommendation Service (CPU% and Memory), Service Latency (from SpanMetrics), Error Rate를 유심히 살펴보도록 하겠습니다.
Recommendation Service는 Opentelemetry 메트릭을 Prometheus로 내보낸 데이터를 기반으로 생성되고, Service Latency 및 Error Rate는 OpenTelemetry Collector의 Span Metric Processor를 통해 생성됩니다.

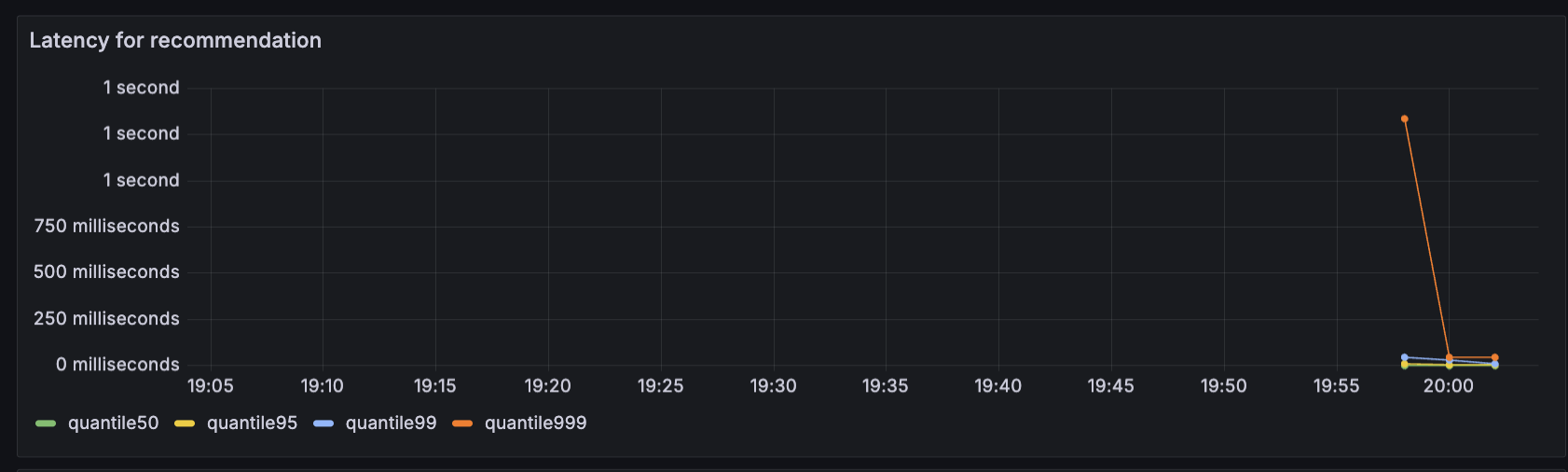
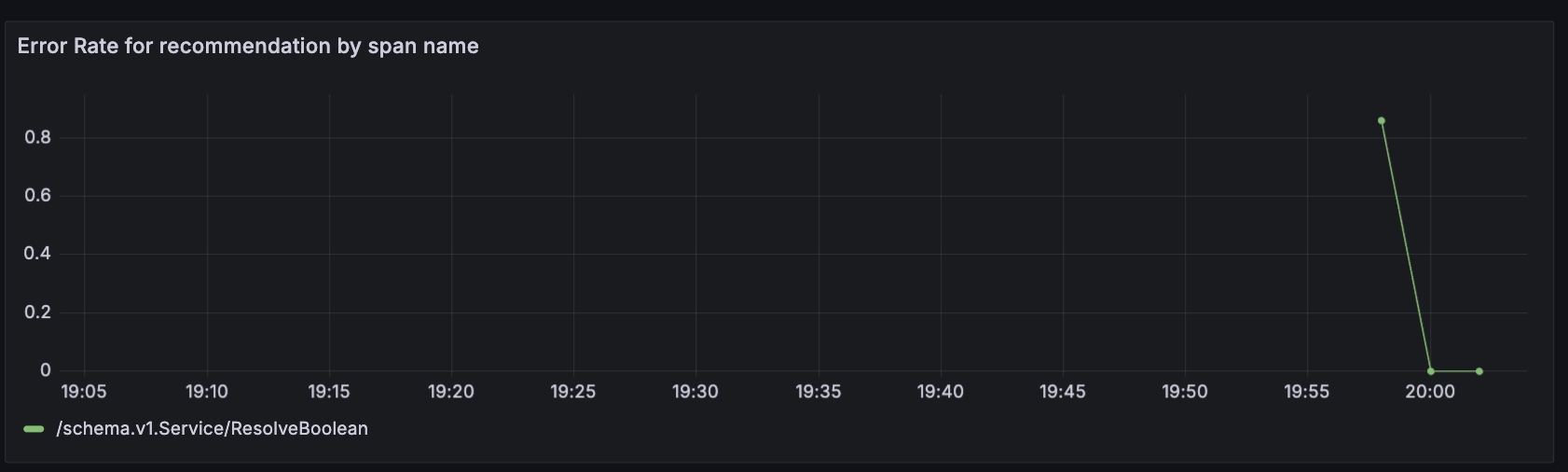
현재는 특별한 문제가 없는 것을 확인하실 수 있습니다.
flag-config 수정
해당 실습을 진행하기 위해 OpenTelemetry 데모에서 제공하는 여러 실습 설정 값 중 recommendationCacheFailure 옵션을 활성화합니다. 이 옵션을 활성화하면 캐시 크기가 약 1.4배씩 기하급수적으로 증가하며, 전체 요청의 50%에서 캐시 증가가 트리거 되어 메모리 누수가 발생하는 상황을 시뮬레이션할 수 있습니다.
kubectl edit cm flag-config
해당 옵션은 flag-config에 configmap에 설정되어 있기 때문에 해당 configmap을 아래와 같이 수정해 줍니다.
apiVersion: v1
data:
demo.flagd.json: |
{
"$schema": "https://flagd.dev/schema/v0/flags.json",
"flags": {
...
"recommendationCacheFailure": {
"description": "Fail recommendation service cache",
"state": "ENABLED",
"variants": {
"on": true,
"off": false
},
"defaultVariant": "on" # 이 부분을 On으로 수정
},
...
}
그 후 pod를 재시작해줘야 해당 config가 적용이 됩니다.
대시보드 확인

일정 시간이 지난 후 (대략 3분?) dashboard를 확인해 보면 Latency, Error Rate, Request값이 급격히 증가하는 것을 확인하실 수 있습니다.

이제 grafana를 통해 메트릭 지표상 문제가 생겼다는 것을 확인했으니 Trace 지표를 확인해 보겠습니다.

여러 trace에서 recommendation service의 문제가 있다는 것을 확인하실 수 있습니다.

위와 같이 특정 trace를 클릭하여 특정 오류의 세부 정보를 확인하고 오류와 관련된 로그에 접근할 수도 있습니다.

현재 발생한 에러 로그를 분석한 결과, recommendationServiceCacheFailure 옵션이 활성화됨에 따라 캐시 크기가 급격히 증가하였고, 전체 요청의 50%에서 캐시 증가가 트리거 되어 이로 인해 서비스가 정상적으로 운영되지 못하고, 메모리 과부하로 인해 gRPC 요청을 받을 수 없는 상태가 되었다는 것을 알 수 있습니다.
마무리
위 실습을 통해 Metric과 Trace를 활용하여 특정 이슈(여기서는 메모리 누수)를 확인하고 분석하는 과정을 진행했습니다. Grafana에서 생성된 Dashboard를 통해 메모리 사용량 증가와 성능 저하를 확인하고, Jaeger를 통해 Recommendation Service에서 비정상적인 Trace를 발견하여 로그 분석을 통해 gRPC 서비스 장애라는 원인(구체적으로는 캐시 과부하로 인한 Crash)을 파악해 볼 수 있었습니다.
참고
https://opentelemetry.io/docs/what-is-opentelemetry/
What is OpenTelemetry?
A short explanation of what OpenTelemetry is and isn't.
opentelemetry.io
https://github.com/open-telemetry/opentelemetry-demo
GitHub - open-telemetry/opentelemetry-demo: This repository contains the OpenTelemetry Astronomy Shop, a microservice-based dist
This repository contains the OpenTelemetry Astronomy Shop, a microservice-based distributed system intended to illustrate the implementation of OpenTelemetry in a near real-world environment. - ope...
github.com
https://opentelemetry.io/docs/demo/feature-flags/
Feature Flags
The demo provides several feature flags that you can use to simulate different scenarios. These flags are managed by flagd, a simple feature flag service that supports OpenFeature. Flag values can be changed through the user interface provided at http://lo
opentelemetry.io
'스터디 이야기 > 25' AWS EKS' 카테고리의 다른 글
| EKS에서 ConfigMap 없이 API로 접근 관리하기(Cluster Access Management) (2) | 2025.03.14 |
|---|---|
| KWOK를 활용한 Kubernetes AutoScaling 테스트 환경 구축 (1) | 2025.03.08 |
| 모니터링 vs 관측가능성, 그리고 SLI·SLO·SLA (0) | 2025.02.28 |
| VolumeSnapshot & SnapScheduler로 Kubernetes 볼륨 자동 백업하기 (0) | 2025.02.22 |



